MediaPipe Hands 文章閱讀
MediaPipe Hands: On-device Real-time Hand Tracking
本篇為 google 的作品,為了能在手機上使用而開發。
作者 : Fan Zhang, Valentin Bazarevsky, Andrey Vakunov, Andrei Tkachenka, George Sung, Chuo-Ling Chang, Matthias Grundmann
摘要 (Abstract)
本篇為 MediaPipe 架構的一個應用, MediaPipe 為一個,跨平台機器學習框架。
網路結構分為兩個模型,第一個階段為手掌偵測 ( palm detector ),第二個階段為手部定位點 ( hand landmark ) 偵測,藉此能透過彩色影像 ( RGB ) ,預測出手掌骨架, 作為後續 AR/VR 之應用。
本篇的網路模型與架構能在手機等移動端設備上達到即時 ( Real-time ) 執行的效果。
同時相關的程式碼有開源在後方連結中 https://mediapipe.dev 。
1. Introduction
在 AR/VR 的應用中,手部追蹤有著重要的地位,在工業上長期是研究的重點之一。
目前大部分的研究,都需藉由額外的硬體設備來執行,例如透過深度感測器等等,並且模型大小都不夠輕量化,難以在移動設備上運作。
本篇文章的重點貢獻有以下幾點
- 效率極佳的兩階段手部追蹤,能在移動設備上同時偵測多個手掌
- 僅透過彩色影像 ( RGB ) ,辨識出 2.5D 的手勢
- 能在多個平台上執行的,開源的手部追蹤系統 ( 能在 Android, iOS, Web, PC 等等 )
2. 模型結構 ( Architecture )
本文的方法運用了,兩個機器學習模型。
- 手掌偵測 : 透過全圖影像,標記出手掌的位置 ( bounding box )
- 手部定位點偵測 ( hand landmark ) : 透過前一個模型,擷取的手部框,預測 2.5D 的定位點
透過擷取出的手部框來預測定位點,能大幅的減少資料擴增 ( Data augmentation ),並能使模型專注於定位點的預測。
在實際執行的過程中,只有第一次與手部追蹤追丟時,才啟用手掌偵測的模型,其餘時間皆使用前一幀 ( frame ) ,所預測的定位點轉換出的方框來執行。
2.1 手掌偵測模型 ( BlazePalm Detector )
作者們採用類似 BlazeFace 的模型結構,來執行手掌偵測。
本文的網路可以偵測不同大小的手、被遮擋的手、被另一隻手遮住的手等等,然而僅憑視覺特徵來判斷手部,相較於擁有眼、嘴等特徵的臉部偵測是更加困難的,作者們透過一些技巧來克服以上的難處。首先作者們選擇偵測手掌而非手部,可以稍微降低偵測的難易度,再者僅透過正方形,而非長方形來標定位置,稍微地降低了定位點數量。再來作者們採用了類似 FPN 的編解碼 ( encoder-decode ) 方式進行特徵提取,使網路能偵測大的跟小的手掌。最後縮小了 Focal Loss 使網路能提供較大變異度的定位點。
下方為網路的結構
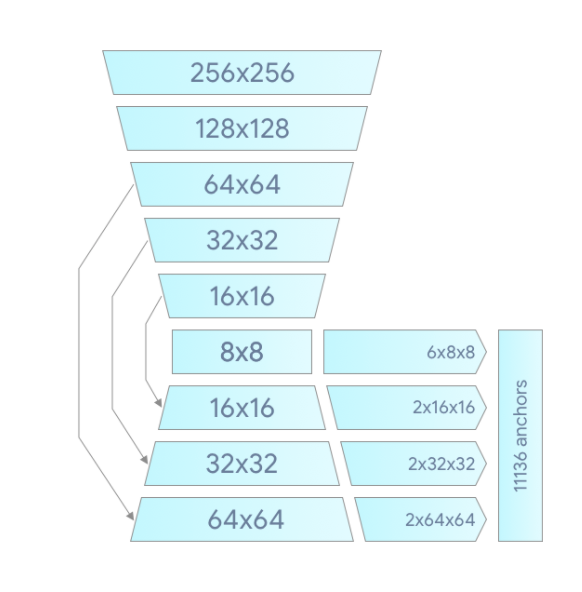
2.2 手部定位點偵測模型 ( Hand Landmark Model )
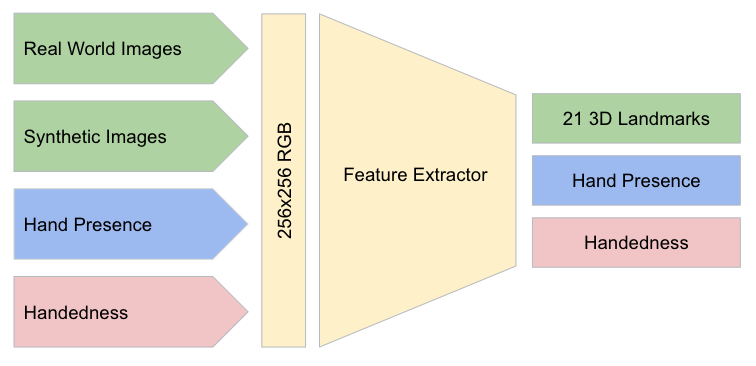
經過第一階段的手掌偵測,第二階段的手部定位點偵測模型,透過回歸的方式,能穩定的取得 21 個 2.5D 定位點 ( 即使在部分遮擋,或是被另一隻手掌遮擋皆可以辨識 )。
模型有三個輸出
- 21個座標點 ( x, y ) 與相對深度
- 手是否出現 ( hand flag ) 顯示圖片中是否有手
- 慣用手辨識 ( handedness )
坐標點透過現實的影像 ( real-world images ),與擁有深度資訊的合成影像來學習 ( 手腕的坐標點只有合成影像有 )。辨識手是否出現,來判斷切出來的圖片裡是否包含手,需不需要重新辨識。慣用手的辨識在部分的 AR/VR 的應用中十分有幫助。
為了不同的使用環境,作者們開發了三總模型,輕量的、一般的、巨型的,來符合不同的使用環境。
3. 資料集與標記 ( Dataset and Annotation )
作者們透過以下的方式取得資料集
- 戶外資料集 ( In the wild dataset ) :此資料集擁有 6000 張圖片,富有場景多樣性、光線強度多樣性、不同的手掌,缺點是沒有複雜的手勢。
- 室內資料集 ( In house collected gesture dataset ) :此資料集擁有 10000 張圖片,涵蓋大量不同角度的手勢。缺點是僅有 30 個人的手,並且背景變化也不大。
- 合成資料集 ( Synthetic dataset ) : 為了能取得更多的角度與額外獲得深度資訊,作者們模擬了手的模型並搭配不同的背景來合成。作者們採用商業用的 3D 手部模型,他由 24 塊骨頭組成,與 36 個形狀,用於控制手掌與手指的厚度等等。並提供 5 總材質的皮膚,與不同的皮膚顏色深度。作者們製作了一段各總手部動作的影片,從中擷取了 10 萬張影像,並且渲染了不同的背景光線,與採用不同的攝影機,如下圖所示。

手掌偵測模型僅採用「戶外資料集」訓練,而手部定位點偵測模型則採用了所有資料集訓練。
4. 結果 ( Results )
於手部定位點偵測模型 ( Hand Landmark Model ),實驗顯示結合實際資料集 ( Real-world datasets )與合成資料集 ( synthetic datasets ) 能達到最好的效果。
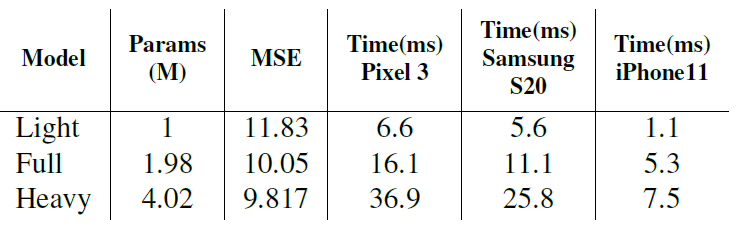
如下表所示,結合合成資料集可以使準確度提升,並且降低在每幀之間的跳動。

作者們的目標是在行動裝置上執行,所以他們實驗了三總不同大小的模型 ( 如下表所示 ),於 Full 版本中,能在準確度與速度上達成平衡。
5. 透過 MediaPipe 執行 ( Implementation in MediaPipe )
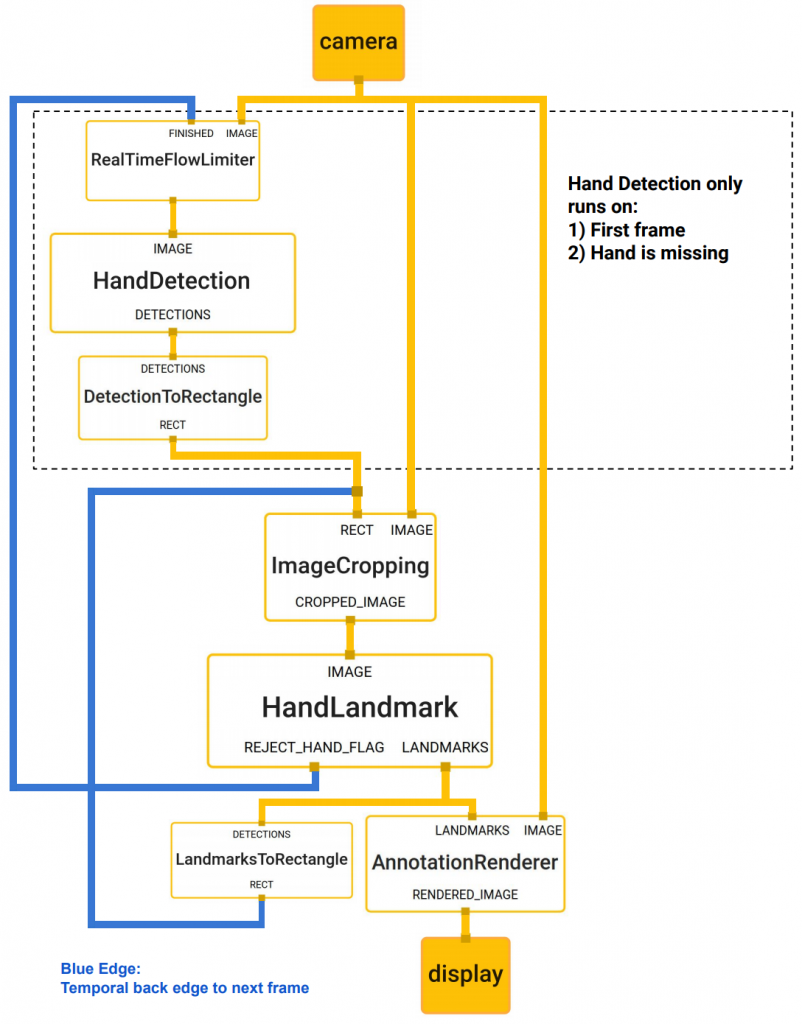
透過 MediaPipe,我們可以使模型拆分成幾塊模組。 MediaPipe 擁有可延伸的模組,能解決模型推論 ( model inference )、多媒體處理 ( media processing ) 、 跨平台資料轉換等等。
本文的結構圖如下所示,由一個手部辨識與坐標點計算所組成。為了節約計算時間,手部辨識僅在第一次時或是手部追蹤追丟時執行,其餘時候由坐標點回推來計算,能大幅地降低執行時間。
6. 應用範例 ( Application examples )
此模型能方便的應用於多個地方,如手勢辨識與 AR 應用等等。
手勢辨識 : 透過辨識完的骨骼,我們可以透過計算彎取、伸直等辨識手勢。

AR 應用 : 可以透過霓虹燈來渲染骨骼,產生酷炫的效果。

7. 總結 ( Conclusion )
在本篇文章,作者們提出了 MediaPipe Hands ,能透過簡單的圖片,不需要額外的硬體,就能辨識手部坐標點,能輕鬆的在各個裝置上執行。希望能讓研究員與工程師們生產出更多的手勢控制與 AR / VR 應用。