SiamFC 文章閱讀
Fully-Convolutional Siamese Networks for Object Tracking
此篇開啟了採用孿生網路( Siamese Network ),處理追蹤(Tracking) 問題的研究方向。
作者 : Luca Bertinetto, Jack Valmadre, João F. Henriques, Andrea Vedaldi, Philip H. S. Torr
摘要 (Abstract)
對於追蹤任意物體的任務之中,傳統上時常採用該影片本身當作訓練資料,單純以線上的方式來學習物體表面特徵。
儘管這個方法十分的成功,但線上學習的原理,大幅限制了模型能學習到的豐富程度。
近期有大量的研究嘗試以 CNN ( Convolutional Neural Networks ) 來處理相關問題,然而被追蹤的物體不能預先知道,所以僅能採用 SGD ( Stochastic Gradient Descent ) 以線上的方式來調整網路參數,大幅增加了系統的執行時間。
在本篇文章中,我們採用了全卷積孿生網路 ( Fully-Convolutional Siamese Networks ) ,透過 ILSVRC15 資料集,來訓練物體追蹤網路,我們的網路執行上比即時速度 ( real-time ) 還要快,儘管他如此簡單,但在多個指標上仍達到了最佳的成績。
1. Introduction
我們假設問題為,追蹤影片中的任意物體,該物件會在第一幀 ( Frame ) 以矩形框標示。演算法可能需要追蹤任意的物體,但我們難以取得足夠的任意物體資料來做為訓練數據,訓練特定的檢測器。
多年來,大多數成功的演算法,採用的是,提取自該影片本身的訓練資料,於線上學習該物體的外觀來達成的。這類演算法大多歸功於 TLF, Struck, KCF 等出色的展示能力。然而從該影片提取訓練資料的方式,明顯只能訓練出相對簡易的模型。
雖然在計算機視覺領域,越來越多問題採用深度卷積網路來解決。但在物體追蹤領域,因為訓練資料的不足與運算的即時性,較難以訓練出針對各別影片的物體追蹤器。
近期有許多文章針對這個限制進行解決,它們採用預訓練好相似任務的模型來執行。第一類為採用correlation filters 透過模型本身的表達能力來執行,缺點是無法完整利用端到端學習的特點;另一類為採用SGD 來調整網路,雖然能達到很好的效果但大幅限制了執行的速度。
作者們採用相似性比較來處理這個問題,透過一個全卷積的孿生網路,輸入圖片( search image )與被搜索物體 ( exemplar ) ,提取特徵,並透過緊密又有效率的滑窗(sliding-window),執行互相關( cross-correlation ) ,定位被搜索物體的所在位置,這始得速度能有非常大的提升。
作者們斷言,相似學習的做法,因為缺少大量的已標記資料,而長年被相對忽略。
事實上,直到最近可使用的資料集也僅只有幾百個標記的影片。然而我們認為 ILSVRC 資料集的出現,讓我們能訓練這樣的網路。此外透過同支影片來訓練與測試物體追蹤,是個被受爭議的作法,近期已經被 VOT 協會所禁止。 我們於 ImageNet Video domain 訓練,並於 ALOV / OTB / VOT domain 進行測試。
2. Deep similarity learning for tracking
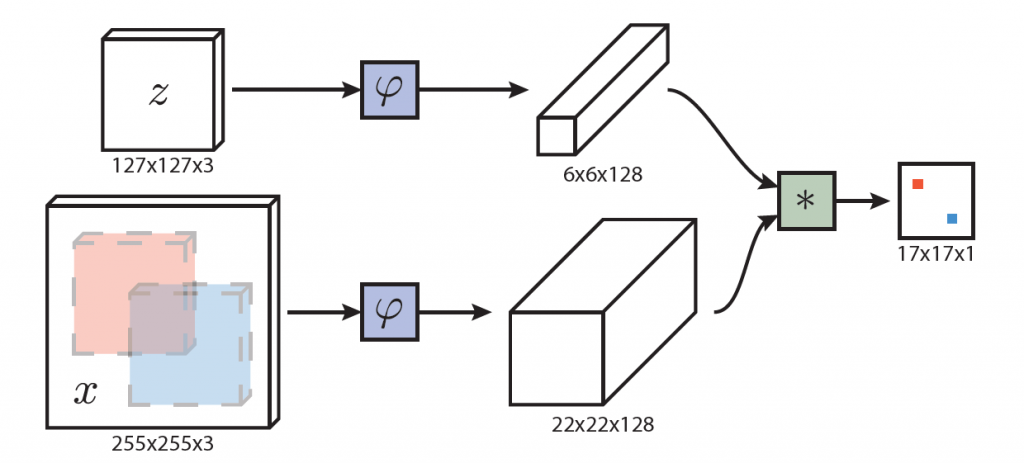

追蹤任意物體的任務可以視為相似性任務來處理。
我們訓練一個函數 f (z ,x) 來比較 z 與 x 之相似性, z 代表要被追蹤的物體( examplar image ) , x 代表整張要被搜索的影像 ( candidate image ),如果兩者相似即回傳高的分數,反之則低的分數。
尋找位置的方式為,測試所有可能的位置,選擇相似性分數最高的點。在實驗中我們單純採用最初選取的物體( examplar image ) 進行搜索。函數 f 為透過具有影片與物體軌跡的數據集進行訓練。
在相似性領域中通常採用孿生網路 (siamese) 來進行處理,孿生網路透過相同的變換 φ 對兩個數入進行一樣的處理,並透過距離函數(相似性指標) g 來對兩個輸出進行結合,f (z, x) = g( φ(z), φ(x) )。 孿生網路大量應用於人臉驗證( face verification )、關鍵點描述學習( keypoint descriptor )、單次字元辨識等領域(one-shot character recognition)。
2.1全卷積孿生網路架構 ( Fully-convolutional Siamese architecture )
假設網路全部為轉換結構 ( commutes with translation ),即為全卷積網路。
這個好處是我們可以採用更大的被搜索影像 ( candidate image ),不需要受到被追蹤物體( examplar image )大小的限制,並會在最後,一次性計算所有網格的相似程度,最後會輸出一個二維的分數圖。
在追蹤過程,我們會把被搜索影像放置於先前目標物的位子,並透過比較最大分數與中心圖的距離,在乘上步輻( stride ) ,以求出每幀之間的位移。
最後一步的逐步互相關 ( cross-correlation ) ,與捲積的效果相同,故我們把追蹤影像( examplar image ) ,當成捲積核,於被搜索影像上 ( candidate image ),進行捲積。
2.2訓練大型搜索圖片 ( Training with large search images )
作者們採用 Logistic loss,來訓練判別器 ( discriminative ) , v 代表預測分數,y 代表標籤 (label) 。
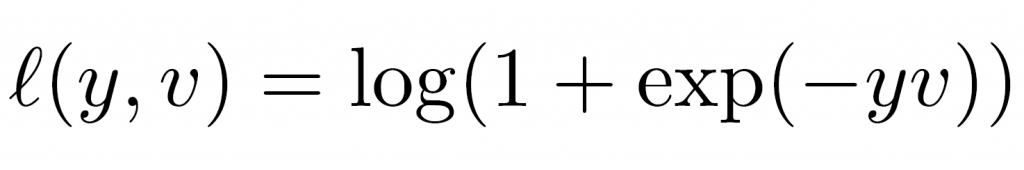
並逐點計算平均值
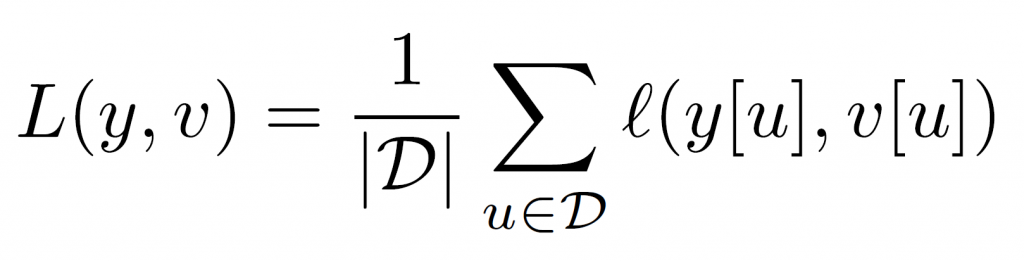
訓練是採用SGD ( Stochastic Gradient Descent ) 來收斂網路。
被追蹤物體與搜索影像取得方式,為擷取影片中距離 T 幀 ( frame ) 的兩張影像,並以目標為中心點,不考慮物體的類別。並在不破壞影像比例的情況下對影像進行標準化( notmalization ),如果物體在中心點半徑 R 內,我們即視他為正樣本。
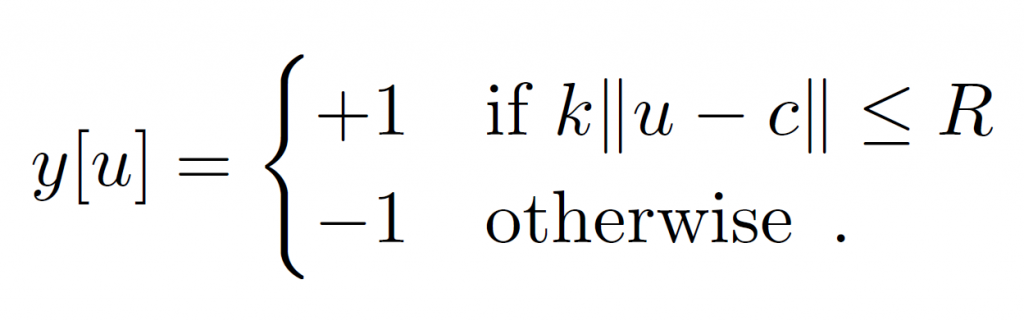
雖然全卷積網路,可以採用不同大小的,被追蹤物體( examplar image ),但在此我們假設他的大小是統一的,之後也許可以放寬標準。
2.3 ImageNet Video for tracking
ILSVRC 2015 ( ImageNet Large Scale Visual Recognition Challenge ) 新加入了 ImageNet Video 數據集,當成一個在影片中偵測物體的挑戰。挑戰者需要分類與定位 30 個類別的動物與交通工具。訓練集(Training Set) 、 驗證集 ( Validation Set ) 共包含了接近 4500 支影片,總共有 100萬幀標註好的影格。這數量與 VOT, ALOV, OTB 等數據集相比是非常驚人的。
我們認為ILSVRC將會引起追蹤領域的注意,因為他擁有龐大的資料,與不同以往經典指標的背景與物件。
2.4 實際應用上的考量 ( Practival considerations )
a . 資料部分 ( Dataset curation )
在訓練階段,我們採用 127 x 127 大小的追蹤影像( examplar image ),255 x 255 大小的被搜索影像 ( candidate image )。影像裁切方式為選取方框 ( w x h ) ,並多選取四周一定範圍的像素 p , p 的計算方式為 p = ( w + h ) / 4 ,在乘上一個比例參數,變成 A ( 127 x 127 或 255 x 255 ),公式如下。
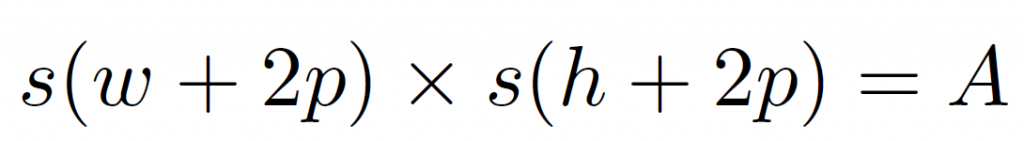
影像都是離線擷取的,以防止在訓練過程中,需要重新調整大小,在早期的版本中我們有採用一些策略,限制從影片提取的影像幀數,來做為訓練數據。在本文中的實驗皆是選取 ImageNet 中全部 4417 支影片( 超過200萬個標記 ),進行訓練。
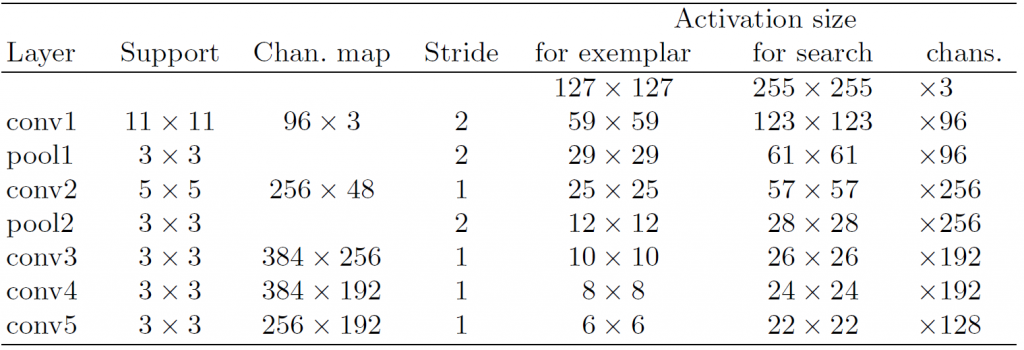
b. 網路結構 ( Network architecture )
網路採用 Alex Net 中,卷積的部分,詳細結構如下表所示,前面兩層卷積後面都接了 Max pooling 。並且除了最後一個卷積層之外每一層結尾都加上了非線性的 ReLU 激活函數。在訓練的過程中每一個線性層後面都接了一個 BN 層 ( Batch Normalization ) 。有一個重點是本網路皆未加 padding 因為 padding 違反了全卷積的概念。
c. 追蹤演算法 ( Tracking algorithm )
作者們採用較單純的演算法,不執行模型更新與紀錄前面數幀影像 ( frame ),也沒有搭配而外的特徵,如光流 ( optical flow )、直方圖 ( Color Histograms ),並且沒有特別調整預測的外框 ( bounding box ),儘管如此,他仍取得了十分傑出的效果。
另外為了速度,作者們僅針對前一幀四倍大的區域進行搜索,並且採用餘弦窗 ( Cosine Window ) 對於較大的位移進行抑制 。
3. 相關研究 ( Related work )
近期一些研究採用 RNN ( Recurrent Neural Networks ) ,來處理追蹤問題。
如 Gan 等人,訓練一個 RNN 網路,判別每一幀影像中目標物的絕對位置; Kahou 等人也是採用類似的方法,使用 differentiable attention mechanism 訓練 RNN。 很可惜的是,這些方法沒有展示出,足以跟其他方法相比的效果,但他們開創了未來一個研究的方向。我們發現了一個有趣的共通點,我們的孿生網路可以解釋為展開的 RNN 網路,在兩倍的序列中訓練與驗證。
Denil 等人,採用粒子濾波器,透過學習好的距離測量標準,比較第一幀與後面的每一幀影像,但他們的做法與我們比較整個物體不太相同,是比較物體內一定的小範圍而已。為了學習距離測量標準,他們訓練了一個有限波茲曼機 ( RBM- Restricted Boltzmann Machine ) ,然後使用歐式距離 ( Euclidean distance ) ,在兩格隱藏激活函數之間 。雖然波茲曼機是非監督是算法 ( unsupervised ) ,但他們仍建議,透過要檢測對象中心的隨機點訓練。這方法需要在線學習,或是知道物體外觀才能離線使用。除了 MNIST 數字外,此方法僅在人臉與行人追蹤上得到驗證。
雖然為每個影片,重新訓練一個特定的網路模型是不太可行的,但不少研究採用了預訓練網路,再進行微調的方式來達成。如 SO-DLT、MDNET,就是先離線訓練一個類似任務的網路,在執行時透過 SGD 微調,這類的方法在執行上會比較慢。有個折衷的方式是同時結合網路與傳統算法,如 DeepSRDCF、 FCNT 等,但因網路的維度過高,仍不能達到即時的速度。
跟我們同期,也有其他作者採用一對影像訓練捲積網路 ( Conv net ),執行物體追蹤的問題。Held 等人,開發了 GOTURN 網路,透過捲積網路回歸出矩形位置。優點是可以處理長寬比等問題,不需要詳盡的評估,但需要大量的資料增強 ( Augmentation )。 Chen 等人,訓練了 YCNN 網路,Y 指的是網路的形狀,他們網路最後面,是全連接 (Fully connected) 的結構,這代表了他們的圖形大小於訓練時就指定了,不能任意變換。Tao 等人推出了 SINT ( Siamese INstance search Tracker ) 網路 ,同樣採用孿生網路的形式,但他們導入了光流 (Optical Flow) 與外框回歸 (Bounding Box Regression) 等技術 ,以增加準確度,雖然採用了 ROI Pooling 等方式提高效率,但執行上仍只有 2 幀每秒的速度。
上述的方法 ( MD-Net、SINT、GOTURN ),皆是採用 ALOV、OTB、VOT 等訓練網路,作者們在此篇文章中還驗證了在不同的資料域訓練,仍能達到好的結果。
4. 實驗階段 (Experiments)
4.1 Implementation details
Training : 網路採用 MatConvNet ,參數為高斯分布,透過 SGD 迭代更新參數。總共迭代 50 輪,每一輪使用 50000 對影像,每次使用 8 個一組的 mini-batches,學習率 ( Learning Rate ) 從 10-2 遞減到 10-5。
Tracking : 整個流程盡量的簡化, 最初的影像外觀僅於第一次執行時計算。並透過雙三次插值 (Bicubic interpolation) 上採樣分數圖,從 17×17 到 272 x 272,能取得較準確的定位。
對目標物進行五總尺度的搜尋1:025{-2,-1,0,1,2}
作者們有開源 SiameseFC 的程式碼,載點如下
http://www.robots.ox.ac.uk/~luca/siamese-fc.html
作者們的電腦是 Intel Core I7-4790K 搭配 NVIDIA Titan X ,可以達到 86/58 幀 每秒 ( 3/5 scales )
4.2 Evaluation
實驗分為五個尺度和三個尺度,分別稱為SiamFC、SiamFC-3s。
4.3 The OTB-13 benchmark
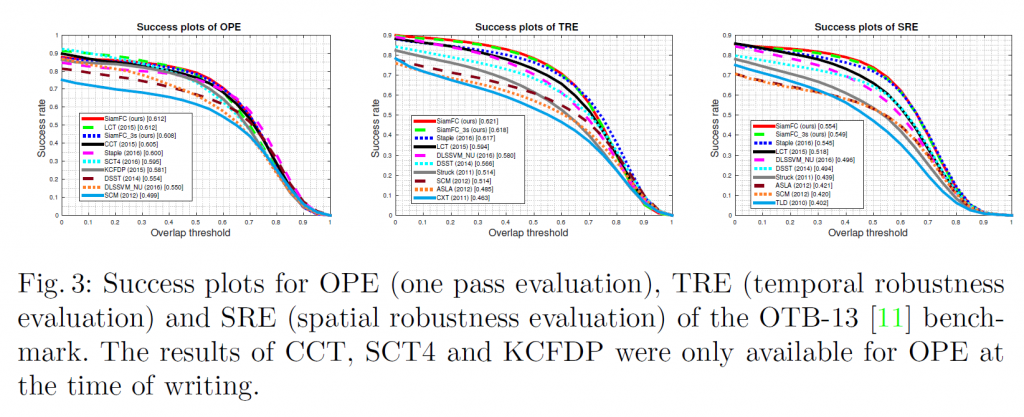
OTB-13 考慮了不同域值得每幀準確度,透過預測範圍與標籤之間的 IoU ( Intersection-over-union ) 大小來計算域值。在 OTB-13 指標,作者們與 Staple、LCT、CCT、SCT4、DLSSVM_NU、DSST、KCFDP 等算法進行比較,比較結果如下圖所示
4.4 The VOT benchmarks
VOT (Visual Object Tracking) 工具包,裡面包含 356 支連續影像,其中有部分來自 ALOV、OTB 數據集,在測試的過程中如果追蹤器追丟了,會在 5 幀後重新初始化。
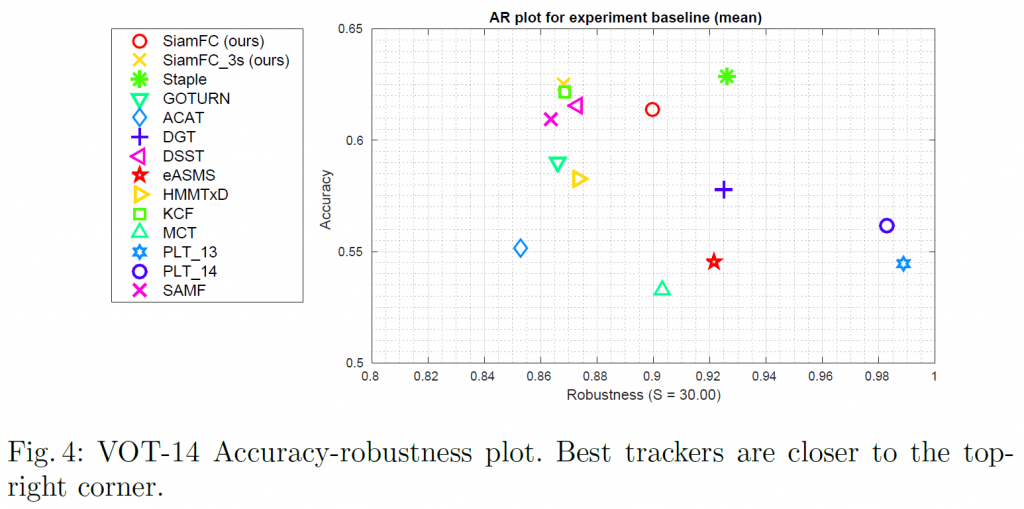
VOT-14 : 作者們與參加 VOT-14 挑戰中,前 10 名的追蹤器進行比較,再而外加上 Staple 跟 GOTURN 兩個發表於 CVPR 2016 跟 ECCV 2016 的文章。採用準確度 (accuracy)、穩定度 (robustness) 進行比較,準確度計算方式為平均的 IoU,穩定度則為總錯誤數,下圖為比較圖。
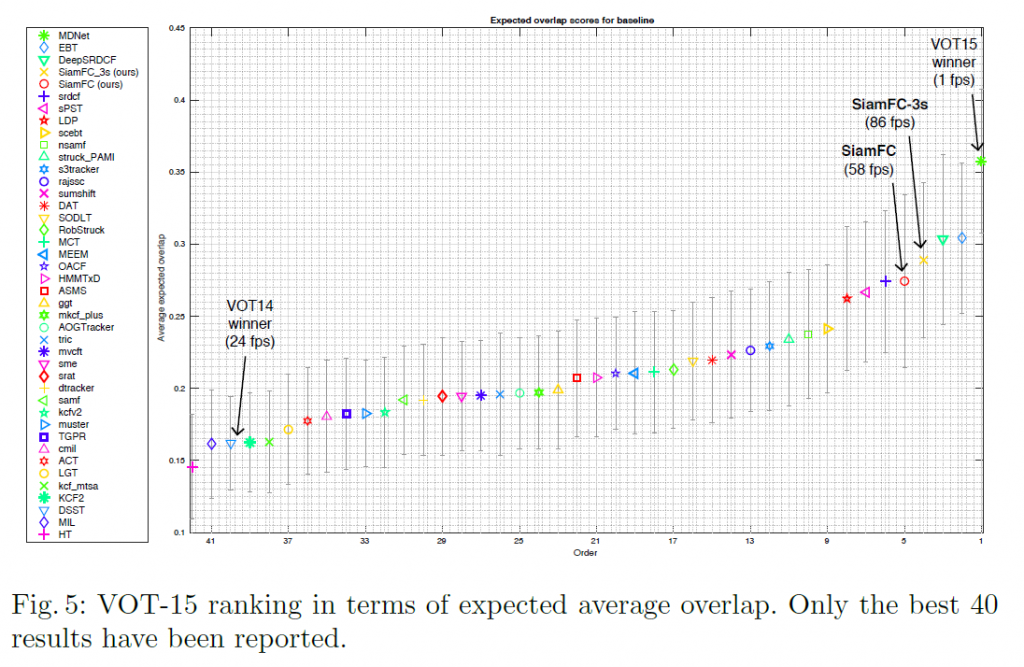
VOT-15 : 作者們與參加 VOT-15 的前 40 名追蹤器進行比較,比較標準為預期平均重疊 (expected average overlap measure),意思為追丟後,沒有重新初始化,情況下的 IoU 值,比較圖如下所示。
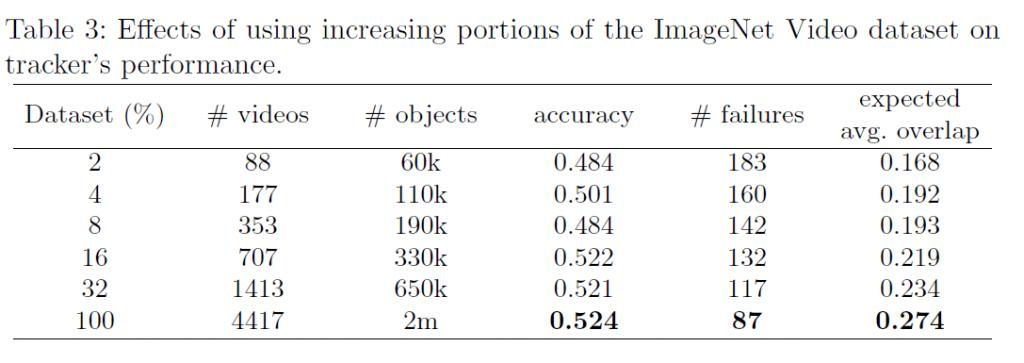
4.5 Dataset size
下表為訓練數據集的豐富程度,與他們所對應的準確度。可以看到越豐富的訓練集能提升越高的準確度。